Worker threads in Node
Recently Node.js released v12.11.0 which has stablized support for “worker threads”. As a programmer interested in concurrency and performance, I was intrigued and had a few questions that I wanted to look into -
- Will Node threads work all my multiple CPU cores?
- How can the threads communicate with each other?
- What kinds of tasks are the worker threads suited to do?
To answer these questions and more, I looked into applying worker threads to solve some random problem. So I looked online and found some public datasets to experiment with. Using worker threads we can now write a program to crunch this data and see how that goes. Coming from India, I downloaded the cricsheet dataset since I can easily imagine some analysis on this.
The IPL (Indian Premier League) data is split into multiple YAML files. Each file has ball-by-ball record of what happened in the match. So we have a classic “map-reduce” problem on our hands. With the threads we can parse each file individually, run some numbers and aggregate this data to get some insight. As an exercise, what we will do is calculate the maximum runs any team has hit in their powerplay (first 36 legal balls in an innings).
I uploaded the data to AWS S3 (just for fun) and so that I can run the program anywhere, the idea is simple -
- Download the files (around 750)
- Each worker gets a file’s content, parses it and reports back the runs hit in the powerplay for that match
- The main thread then selects the match with the maximum runs hit
The TypeScript code for this looks like -
import AWS from 'aws-sdk';import { Worker } from 'worker_threads';
import { aggregateResult } from './aggregateResult';
AWS.config.update({ region: 'eu-central-1', accessKeyId: process.env.AWS_ACCESS_KEY_ID, secretAccessKey: process.env.AWS_SECRET_ACCESS_KEY});
const s3 = new AWS.S3();const Bucket = 'de.rockyj.ipl-data';const results: Array<any> = [];
let processed = 0;let totalNumberToProcess = 0;
const workInThread = (rawData: string, resolve: Function) => { const worker = new Worker('./dist/worker.js', { workerData: rawData }); worker.once('message', message => { results.push(message); processed += 1; if (processed === totalNumberToProcess) { resolve(results); } });};
const processS3Bucket = (s3Data: any, reject: Function, resolve: Function) => { totalNumberToProcess = s3Data.length; s3Data.forEach((content: any) => s3.getObject({ Bucket, Key: content!.Key! }, (err, yamlData) => processS3Object(err, yamlData, reject, resolve) ) );};
const processS3Object = (err: any, yamlData: any, reject: Function, resolve: Function) => { if (!err) { workInThread(yamlData.Body!.toString(), resolve); } else { console.error(err); reject(); }};
new Promise((resolve, reject) => { s3.listObjects({ Bucket }, (err, data) => { if (err) { console.error(err); reject(); }
processS3Bucket(data.Contents!, reject, resolve); });}).then((results: any) => { const { finalResult, mostRunsMatch } = aggregateResult(results); console.log(finalResult); console.log(mostRunsMatch);});
// The result is -// { dates: [ 2017-05-07T00:00:00.000Z ], // runs: // { firstInnings: { team: 'Royal Challengers Bangalore', runs: 40 }, // secondInnings: { team: 'Kolkata Knight Riders', runs: 105 } } }So the Kolkata Knight Riders hit an impressive 105 runs in IPL 2017 in their first 36 balls. The full code for parsing the YAML etc. can be found on Github.
To get straight to the answers -
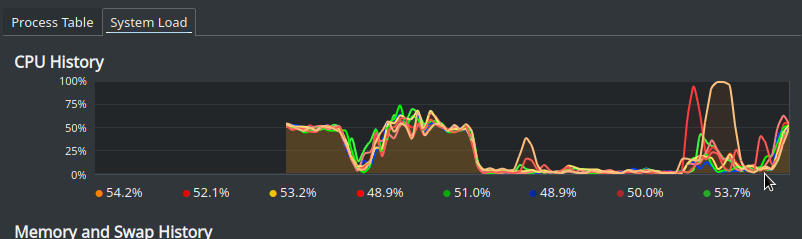
- The performance was quite impressive, downloading, parsing all the files and calculating the result took around 30 secs on my i7 CPU (I did around 10 runs to be sure)
- Node worker threads were able to use all my CPU cores, so there is no Ruby / Python like global lock (GIL)
- The threads can communicate with the parent / other threads through message channels & message ports https://nodejs.org/api/worker_threads.html#worker_threads_class_messagechannel
- The documentation clearly mentions -
Workers (threads) are useful for performing CPU-intensive JavaScript operations. They will not help much with I/O-intensive work. Node.js’s built-in asynchronous I/O operations are more efficient than Workers can be.So our experiment actually did the right thing. I imagine that doing heavy IO operations in the worker threads will not go down well.
Actual proof of CPU usage -
Maybe in the next round I will see how the JVM performs on the same experiment.