AWS Lambda - From skeptic to enthusiast
Back in 2019, I was having a discussion with a friend about using AWS Lambdas and we could not find a real use case for it. For user facing APIs I felt it would be too slow and may have unpredictable performance & billing for commercial web applications. Maybe it simplified the DevOps pipeline but it was not something I would consider for building an important application, building a CI/CD pipeline is just something you do for real life applications.
There were (or are) other considerations as well, Lambdas sort of take away the convenience of working locally and shipping the same “stack” on to staging and production servers. For me the ideal stack is where I can run the same artifact locally and on production (and staging) with only a couple of environment variables and configuration files changed, like shipping a Docker image or a JAR file with only the environment variables changed at runtime. So all in all, I was never someone who understood or recommended the Lambda stack to anyone.
But things changed in mid 2020, my team needed to build a something of a “monthly statement service” where we would need to generate a PDF of the user’s transactions and email it to them. This was something that was not triggered by a user request, nor was some user waiting on it. The “workload” was completely concentrated on one day of the month and we needed to do this in parallel for all the users, since doing it one-by-one for each user would take a lot of time. Being a “veteran” programmer coming from a Java / Ruby / Node background, my first thought was to use Quartz / Spring Batch / Sidekiq or Bull but then few colleagues convinced me try building this feature with Lambdas.
Given the features we needed, we realized that we could build this as a series of functions in a pipeline where SQS would be used to invoke and communicate between Lambda groups. It looked something like this -
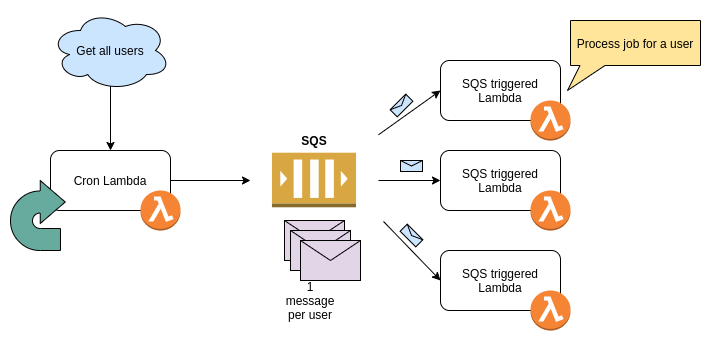
The first cron lambda would invoke iteself on the first day of the month, fetch all the users with a remote call. For each user we created a SQS message and pushed it across. The second set of lambdas (which are triggered by SQS) pick up a SQS message and do the necessary work e.g. get data, generate PDF, send email etc.
The benefit of this approach was that we could scale out wherever / whenever needed. If the number of customers grew to 100,000s we could scale the Lambdas so that the statements could still be sent to all users before they opened thier inbox on 10 AM on the first of every month.
Error Handling
Another big benefit of this approach was error handling. Imagine doing this for 100,000 users with a 99+% success rate, there could always be a few hundred users for which the lambdas would fail (e.g. error in fetching data, error in sending emails). We may want to “re-process” these failed jobs, the SQS DLQ (Dead Letter Queue) works well for this feature. All failed jobs (which were triggered by SQS messages) end up in the DLQ, we can just push these failed messages back to the main queue and re-run the failed jobs. The same applies if there was bug, we can fix the bug and re-process the DLQ.
Final words
Since our setup is just a set of “functions” we could run it locally and it was pretty much the same in the AWS Lambda environment. With a small change in configuration we could scale out to 100s of worker Lambdas and finally only pay for usage for the work we did at the end of every month.
We are really happy with the current architecture, so much so that a few other teams have now adopted it for their “asynchronous” loads.
At the end, I would still say that I would not use Lambdas for everything but there are some cases where they fit perfectly. To summarize -
Lambda Pros -
- 👍🏾 Great for asynchronous, non-user facing tasks
- 👍🏾 Easy to scale out
- 👍🏾 Great for cron jobs where load is for a specific time e.g. nightly / weekly / monthly jobs
- 👍🏾 DLQs make running failed jobs super easy
Lambda Cons -
- 👎🏾 Still not convinced about usage for user facing APIs (e.g RESTful API)
- 👎🏾 Team would still need to learn and deploy a new DevOps stack (apart from a container based stack like K8 / Fargate)
- 👎🏾 Only Node, Python and JVM language support exists
- 👎🏾 Node is not so great for CPU intensive jobs and startup times for JVM are not so good (but if you do not care about latency it’s fine)
- 👎🏾 You lose on stuff like a warm JVM, JIT, connection pools and other advantages that kick in with time / caching since each request sort of spins up a new container / VM
So to conclude, I would not say that I would use Lambdas for every problem but I think I have found a pretty good use case for them and for that it does a great job.